%20-%20%E5%89%AF%E6%9C%AC.png)

RAG 系统中的上下文扩展检索:一些工程实践与权衡
在较长时间的 RAG 系统开发过程中,我逐渐意识到,模型幻觉并不是主要问题,检索上下文不完整反而更容易导致业务错误。
在法规、技术规范或长文档问答场景中,系统经常返回“看起来正确但不完整”的片段,缺少限定条件或后续条款。
直觉上的解决方案是扩大 chunk size,但实践中这带来了新的问题,包括 embedding 粒度下降、检索噪声上升以及 rerank 和生成阶段的 token 成本增长。因此,问题更接近检索策略设计,而不是单纯的参数调优。
Chunk 切分与语义连续性的工程冲突
典型的 RAG pipeline 通常包括:
文档解析与结构化切分
滑动窗口切块与 overlap
embedding 向量化与 ANN 检索
cross-encoder rerank
prompt 拼接与生成
在 FAQ 或短文档场景下,这种 pipeline 工作良好。但在法规文本、论文或技术标准中,语义往往跨段落甚至跨章节连续。
常见失败模式是:定义在一个 chunk,而例外条件或补充说明出现在后续 chunk,检索阶段只命中了前者。
增加 overlap 可以缓解问题,但 overlap 增大意味着索引规模与检索延迟上升,且在实际系统中不可无限扩展。
整体重排的尝试
一个较早的尝试是将 top-K chunk 按文档顺序拼接,作为整体输入 reranker,而不是对单个 chunk 独立评分。
这种方法在跨段落问题上效果明显,模型能够感知 chunk 之间的语义连续性。
但工程代价也很明确:
输入长度不可控,rerank token 成本显著增加
rerank 模型对输入格式敏感,例如 chunk 分隔符或标签格式变化会影响排序结果
truncation 边界变化可能导致关键语义丢失
这些问题使整体 rerank 在生产环境中需要严格格式控制与回归测试。

上下文扩展的实现方式
我们最终采用的上下文扩展策略相对简单,主要作为检索阶段的 heuristic。
Pipeline(简化描述)
阶段 1:初始召回
embedding 检索 top_k(通常 30–100)
FAISS 或 HNSW 索引
阶段 2:第一次重排
将召回 chunk 按文档顺序拼接
使用 cross-encoder 或长上下文 reranker
输出 chunk relevance score
阶段 3:邻域扩展
对 score 排名前 M 的 chunk
扩展前后 1–2 个 chunk
合并连续区间,避免重复输入
阶段 4:第二次重排
对扩展后的 chunk 集合再次排序
选取 top-N 作为最终上下文输入 LLM
参数选择与不确定性
参数选择主要基于经验,没有明确理论最优解:
top_k:30–50 是常见区间,长文档场景可能更大
expansion window:1–2 个 chunk,再大 token 成本明显增加
final_top_n:3–10,依赖模型 context window
不同文档类型差异较大,例如法规文本对扩展较敏感,而 FAQ 数据集扩展往往只引入噪声。
Trade-off:token 成本与检索完整性
上下文扩展直接增加 rerank 和生成阶段 token 使用量。
我们观察到扩展窗口增加时 token 消耗几乎线性增长,而召回增益并不总是线性。
因此在在线系统中引入了简单的动态策略:
当 query embedding 分布较散(问题模糊)时减少扩展
当 query 与某 chunk 相似度极高时才触发扩展
这种策略缺乏严格理论支持,但在生产系统中表现相对稳定。
噪声扩展与文档结构问题
邻域扩展隐含假设文档是线性结构,但现实中并非总是如此:
FAQ 列表
日志或知识库条目
论文附录
在这些场景下,邻域 chunk 语义相关性较低。
一种改进方式是基于 section/heading ID 限制扩展范围,但这需要额外的文档解析 pipeline。
reranker 的稳定性问题
长上下文 reranker 在工程上比 embedding 检索更脆弱:
对 chunk 顺序敏感
对分隔符格式敏感
对 truncation 边界敏感
例如 tokenizer 版本变化导致 truncation 边界移动,可能显著影响排序结果。
在生产环境中通常需要固定 tokenizer 和 prompt 模板,并增加回归测试。
与人类阅读策略的差距
上下文扩展常被描述为模拟人类“前后翻页”,但当前实现更接近局部邻域补偿。
人类会跨章节跳转,而当前 pipeline 通常缺乏 document-level routing 或 graph-based retrieval,这仍是开放问题。
适用场景与限制
基于当前经验,上下文扩展更适合:
法规、政策文本
技术规范与论文
长报告类文档
不太适合:
FAQ 或短知识片段
表格型知识库(结构化查询更合适)
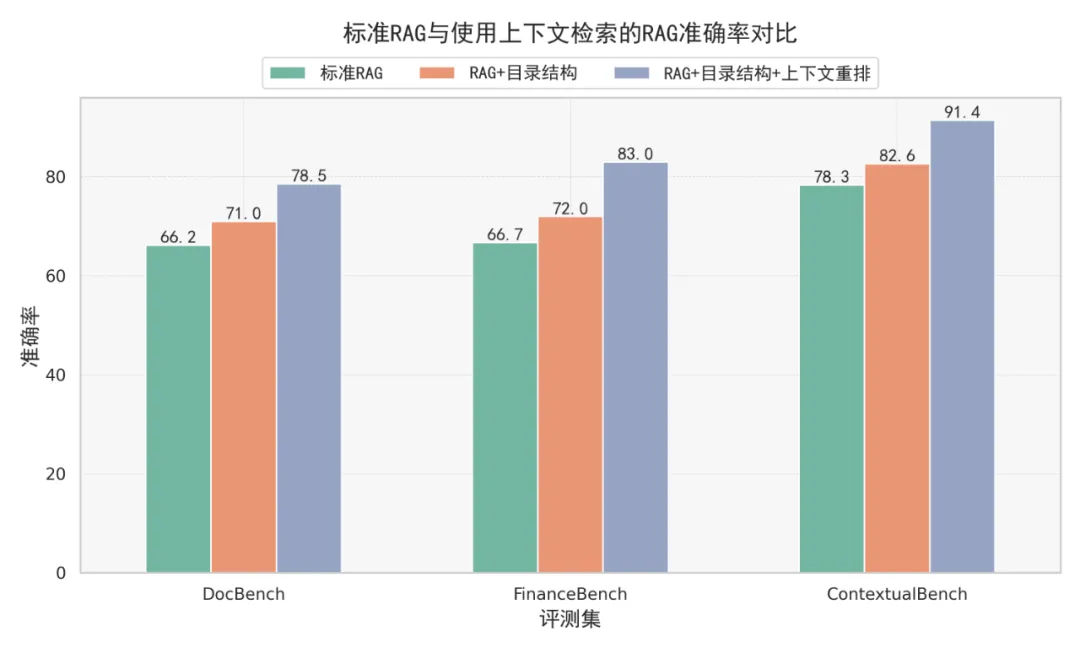
一些暂时性的结论
上下文扩展与二次重排可以改善 RAG 系统回答完整性,但代价是 pipeline 复杂度与 token 成本增加。
在资源受限场景中,优化文档切分与 embedding 模型仍然是优先级更高的工作。
随着超长上下文模型成本下降,chunk-level retrieval pipeline 可能会发生变化,但在当前约束下,上下文扩展是一种可接受的工程折中方案。
评论