
RAG文档召回上下文缺失
more RAG文档召回上下文缺失解决方案
解决RAG中的上下文缺失块问题
开发者们在使用RAG(Retrieval-Augmented Generation,增强检索生成)时面临的很多问题归结为一点:单个块(chunk)中所包含的上下文信息不足,以至于无法被检索系统或大型语言模型(LLM)正确利用。这导致了看似简单的问题也无法得到解答,更令人担忧的是还会产生幻觉(hallucinations)。
这个问题的具体例子包括:
- 块经常通过隐含的指代和代词来提及它们的主题。这会导致应该被检索到的块没有被检索到,或者被大型语言模型误解。
- 单个块通常不包含对一个问题的完整答案。答案可能分散在几个相邻的块中。
- 相邻的块如果呈现给大型语言模型时顺序错误,会造成混淆,并可能导致产生幻觉。
- 过于简单的分块可能会导致文本在“思路中断”的地方被分割,使得任何一个块都没有有用的上下文。
- 单个块通常只有在整体章节或文档的上下文中才有意义,在单独阅读时可能会产生误导。
块 → 段落
较大的块能够为大型语言模型提供更好的上下文信息,但同时也使得精确检索特定信息变得更加困难。一些查询(如简单的事实性问题)最好通过小块来处理,而其他类型的查询(如较高层次的问题)则需要非常大的块。我们需要的其实是一种更加动态的系统,它能够在只需要一小部分信息时检索出短小的块,同时也能在必要时检索出非常大的块。我们该如何实现这一点呢?
将文档划分为章节 关于块来自哪个章节的信息可以提供重要的上下文信息,因此我们的第一步是将文档划分成语义连贯的章节。有许多方法可以做到这一点,但我们将会采用一种基于语义的章节划分方法。这种方法通过标注文档的行号,并提示大型语言模型来识别每个“语义连贯章节”的起始和结束行数。这些章节的长度应该在几段到几页之间。这些章节随后会根据需要进一步拆分成较小的块。
我们将使用Nike公司2023年的10-K报告作为例子。以下是识别出的前10个章节:


块头的目的在于为块文本增加上下文信息。在嵌入和重新排序块时,我们不是仅使用块文本本身,而是使用块头和块文本的组合,如上图所示。这有助于排名模型(嵌入和重新排序器)即使在块文本本身包含隐含的指代和代词,使其含义不清的情况下,也能检索到正确的块。在这个例子中,我们仅仅使用文档标题和章节标题作为上下文。但是有多种方式可以实现这一点。我们也看到使用简明的文档摘要作为块头取得了很好的效果。 让我们来看看块头对于上面展示的那个块有多大的影响。
我们如何利用这些相关块的集群?
核心思想是:相关块的集群,在其原始连续的形式下,能为大型语言模型提供比单个块更好的上下文信息。现在面临的难题是:我们如何实际地识别这些集群?
如果我们能够以这样的方式计算块值,即一个段落的价值仅仅是其组成块的价值之和,那么寻找最优的段落就变成了最大子数组问题的一个版本,这个问题可以通过相对简单的方法解决。我们如何定义块值呢?我们从这样一个观点出发:高度相关的块是有益的,而不相关的块是有害的。我们已经有一个良好的块相关度衡量标准(如上图所示),该标准的取值范围在0到1之间,所以我们所需要做的就是从中减去一个常量阈值。这将使不相关块的值变为负数,同时保持相关块的正值。我们将这种减法称为irrelevant_chunk_penalty。经验表明大约0.2的值效果很好。较低的值会使结果偏向更长的段落,而较高的值会使结果偏向较短的段落。
对于这个查询,算法识别出397-410号块为文档中最相关的文本段落。它还识别出362号块足够相关,可以包括在结果中。以下是第一个段落的样子:  看起来这是一个非常好的结果。让我们仔细看看这段文本中各块的相关性图表。
看起来这是一个非常好的结果。让我们仔细看看这段文本中各块的相关性图表。 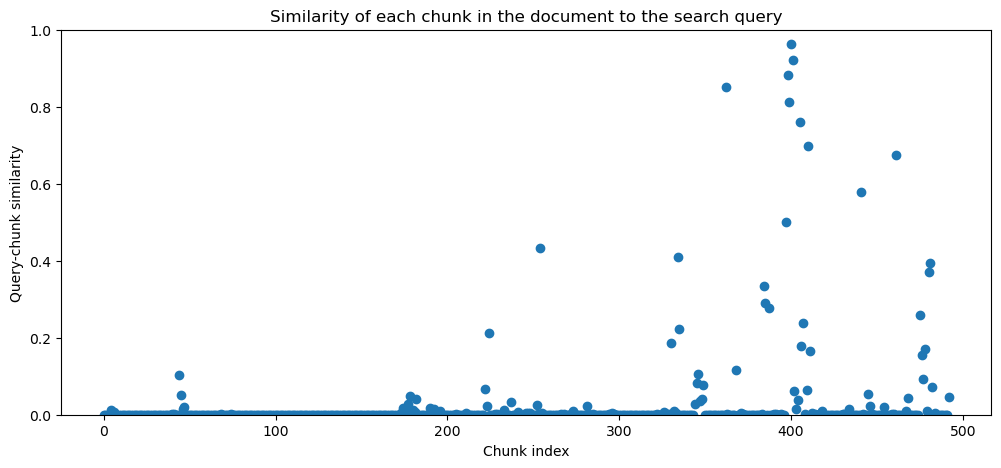 查看这些块的内容,很明显397-401号块是高度相关的,正如预期的那样。但仔细看402-404号块(这部分是关于股票期权的),我们可以看出它们实际上也是相关的,尽管我们的排名模型将其标记为不相关。这是一个常见的现象:那些被标记为不相关的块,但如果夹在高度相关的块之间,通常是相当相关的。在这个例子中,这些块是关于股票期权估值的,所以虽然它们并没有明确讨论基于股票的补偿费用(这是我们搜索的目标),但在周边块的上下文中,可以看出它们实际上是相关的。因此,除了为大型语言模型提供更多完整的上下文信息之外,这种动态构建相关文本段落的方法也使得我们的检索系统对外部排名模型的错误不太敏感。
查看这些块的内容,很明显397-401号块是高度相关的,正如预期的那样。但仔细看402-404号块(这部分是关于股票期权的),我们可以看出它们实际上也是相关的,尽管我们的排名模型将其标记为不相关。这是一个常见的现象:那些被标记为不相关的块,但如果夹在高度相关的块之间,通常是相当相关的。在这个例子中,这些块是关于股票期权估值的,所以虽然它们并没有明确讨论基于股票的补偿费用(这是我们搜索的目标),但在周边块的上下文中,可以看出它们实际上是相关的。因此,除了为大型语言模型提供更多完整的上下文信息之外,这种动态构建相关文本段落的方法也使得我们的检索系统对外部排名模型的错误不太敏感。

